


Introduction
It has been another day of working and prototyping my weird game. Suddenly, I have encountered a huge performance dip.
What is taking so long?
What is taking so long
I ran my program in the same overloaded scene using Samply to capture a CPU profile.
CPU profiles are essentially things that help you figure out what part of the program is
taking too long1. After capturing the profile, I got the following picture about
the game_update:
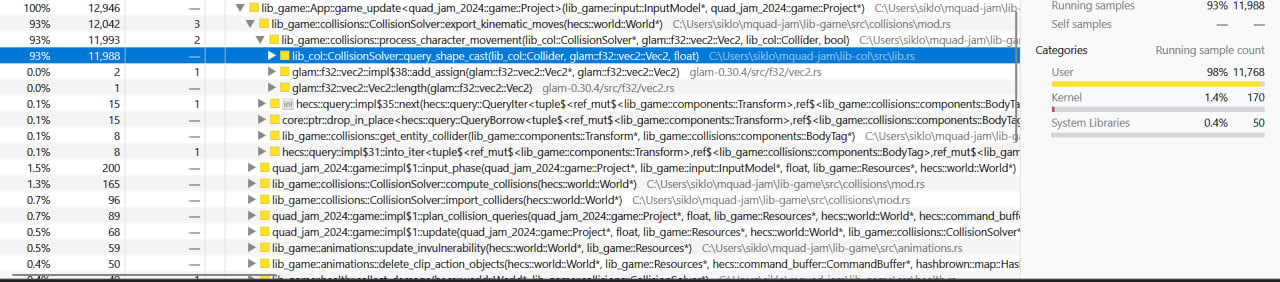
As we can see, the export_kinematic_moves function takes the most time. The function is
part of a larger crate lib-col.
Collisions quickly explained
What's lib-col? It is a lightweight homebrew crate I wrote for doing various collision
checks with a simple API. At its core, all the checks and queries in lib-col are done
internally using the same algorithm based on the Separating Axis Theorem.
The Separating Axis Theorem (from now on referred to as SAT) is a theorem that claims
two convex 2D shapes do not overlap if and only if there is a straight line separating
them. This theorem can then be made computationally feasible by restating it in terms
of projections: two 2D shapes do not overlap if and only if there is a line, on which the
projections of those shapes do not overlap2.
Optimizing
Since all of the queries are done via SAT, the natural movement here is to optimize
the SAT routine itself or augment it with some faster checks. The two main ones I
considered were:
- Use AABBs
- Always build
lib-colwith the highest optimization level
Option (2) is a partial fix, it just makes the CPU churn the same suboptimal code.
Option (1), AABBs, is a solid one. However, it is designed to amortize the existing check,
not speed it up. It will not make the worst case faster. There is in fact
a third option, that can be implemented very elegantly. When lib-col runs a collision
check, it does the following steps:
- Figure out the vertices of both shapes
- Transform the vertices according to shape positions
- Figure out the separating axes
- Try all the separating axes
This is a lot of work for every single collision pair. We can do a quite standard thing here: do steps 1-3 in a special pre-processing step, making the actual collision check very simple:
// Pseudo-code not suitable for legitimate use
colliders_slices:
verts:
normals:
This optimization is really good in many ways: it avoids repeating
the same work over and over, makes shapes_collide more cache friendly and
avoids some branching (we no longer have to branch by the shape type).
With this optimization in place we get the following performance metrics.
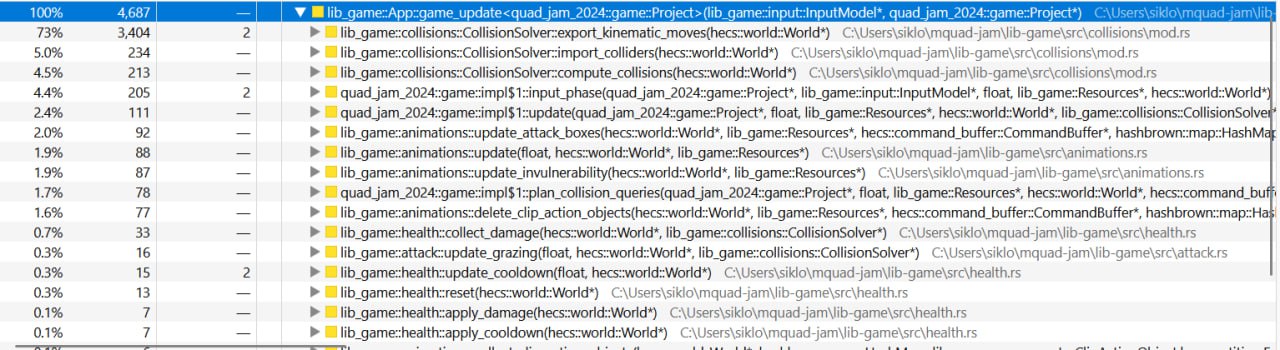
We went down form 93% to 73%. This is a very solid saving. But we can
do better, applying all other things I mentioned before.
More speed
Even for freely rotated rectangles, a pre-check with AABBs is still more optimal
when done right. With that ColliderSlice framework, it is very easy to add AABBs on top.
We can just make it part of the pre-compute step and a part of ColliderSlice:
// Pseudo-code not suitable for legitimate use
It is now the right time to build lib-col with a higher optimization level (the
algorithmic problems have already been explored after all). While doing that
and checking some parts of code via GodBolt I remembered, that the SAT
code was using std::f32::total_cmp internally. Mathematically speaking it was a valid
choice. However, it total_cmp is not a native operation on x86 so it
leads to extra instructions to handle the NaN case properly. Those crutches are somewhat
useless. Computer games never work with NaN, nor should expect it. Given it was
on a very hot path, I opted in for a simple f32 comparison via <, which
generates significantly less instructions and allows for better vectorization.
With all those optimizations in place, that was the final CPU time I got:
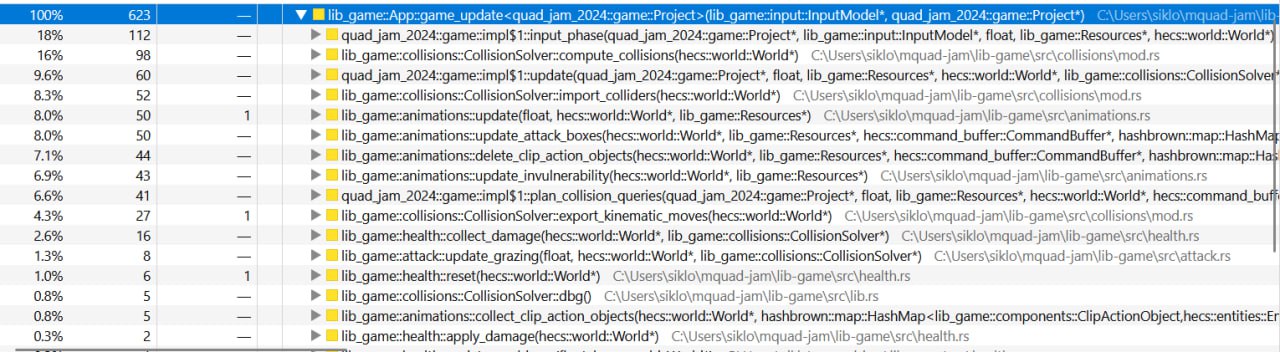
And now export_kinematic_moves wastes only 4.3% of CPU time! Since the total time
spent on a frame also dropped, it is clear that we managed to optimize it even more!
Beware. Sometimes your problem isn't CPU bound, so this information is useless!
A good detailed summary on using SAT.